소프트웨어 및 하드웨어의 성능 향상에 따라 시뮬레이션을 활용하여 제품 개발 비용 및 기간을 단축할 수 있으나 기업의 규모와 무관하게 연산 자원은 한정적이며 R&D 또한 이런 제약조건에 맞추어 진행되는 경우가 많다. Rescale의 클라우드 HPC 플랫폼을 활용하면 제약조건을 뛰어넘어 다양한 조건에서의 시뮬레이션을 신속하게 수행할 수 있다.
Rescale 플랫폼 소개
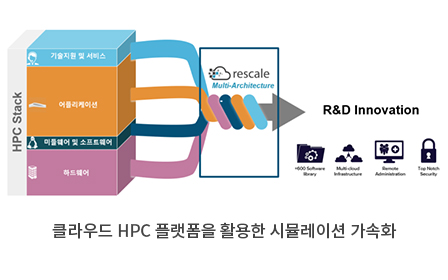
Rescale의 ScaleX는 Public 클라우드의 연산 자원을 기반으로 제품 검증에 사용되는 다양한 소프트웨어가 설치되어 있으며 효율적으로 비용을 관리할 수 있도록 다양한 관리자 기능까지 제공하는 플랫폼으로 기업에서 필요한 HPC의 모든 것을 포함하고 있다.
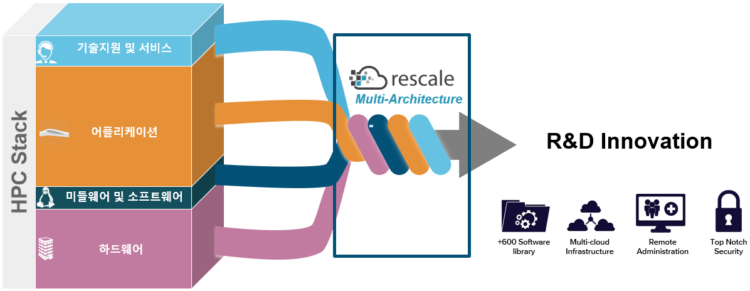
▲Rescale ScaleX 플랫폼은 기업의 HPC 운용에 필요한 A to Z를 단일 플랫폼으로 제공
먼저 소프트웨어의 경우 대부분의 기업들은 제품 개발 시 다양한 소프트웨어를 사용하므로 상용 소프트웨어 외에도 오픈소스를 포함하여 600개 이상의 소프트웨어가 설치되어 있으며(개별 버전을 포함하면 약 10,000개) 사용자는 필요한 버전을 선택하여 사용할 수 있다. 아울러 최신 버전 혹은 기존에 설치되지 않은 소프트웨어의 경우 고객 요청에 따라 설치 가능하며, Rescale 자체적으로 기술지원을 통하여 오픈소스 및 인하우스 코드 또한 사용을 원할 경우 플랫폼에 통합할 수 있다.
다음으로 ScaleX 플랫폼의 강점인 하드웨어의 경우 멀티 클라우드를 지향하며 AWS, Azure, Google, Oracle 등 여러 클라우드 업체와 파트너십을 바탕으로 다양한 코어 타입(서버 유형)을 제공한다. 코어 타입들은 CPU clock speed, Memory/core, Storage/core, Interconnect를 기준으로 분류되며 추가로 고성능 GPU를 탑재한 코어 타입까지 포함하면 78개이며, 사용자는 진행하려는 시뮬레이션에 적합한코어 타입을 선택하여 사용할 수 있다.
아래 그림은 CFD 소프트웨어 중 하나인 STAR-CCM+의 벤치마크 테스트 사례이며, LeMans 1억 격자 모델을 Rescale 플랫폼에서 제공하는 5개의 코어 타입으로 코어 수에 따른 연산 성능 향상 효과를 평가한 결과이다.
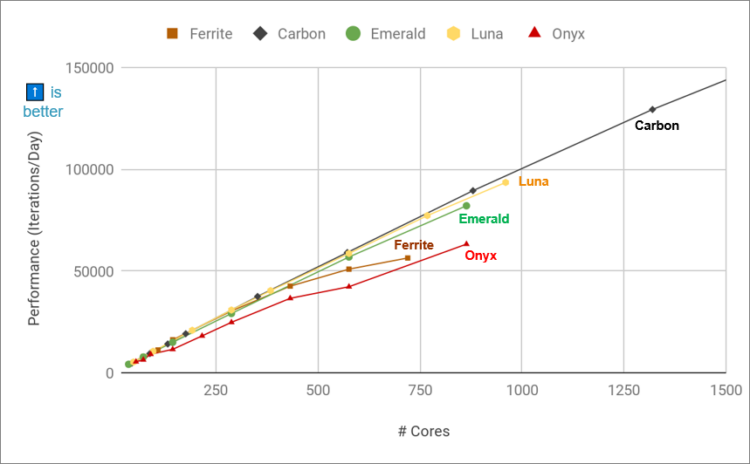
▲Rescale 플랫폼 코어 타입별 코어 수에 따른 STAR-CCM+ 연산 성능 향상 효과
노드간 Interconnect 속도가 빠른 Carbon의 경우 1,000 코어 이상에서도 Scalability가 일정하게 유지되나, Interconnect 속도가 낮은 Onyx및 Ferrite같은 경우 각각 100, 400코어 부근부터 노드간 통신 지연에 따라 코어 수 증가에 따른 연산 속도 향상 속도가 저하되며, Emerald와 Luna는 중간 수준의 Interconnect 속도를 가지고 있어 800 코어 부근까지는 비교적 일정하게 Scalability가 유지되는 것을 확인할 수 있다.
다만 이런 경향성은 시뮬레이션 모델의 크기 및 소프트웨어의 병렬 처리 성능에 따라 달라질 수 있으므로 실제 현업에서 사용하는 모델로 성능 평가를 진행하여 최적의 코어 타입 및 적정 코어 수를 선정하는 과정이 필요하며, Rescale에서는 이런 과정에 대한 벤치마크 테스트 및 컨설팅을 제공하여 고객이 연산 비용을 효율적으로 사용할 수 있도록 지원하고 있다.
코어 타입의 특성에 따른 연산 성능 향상 효과 외에도 전산 자원을 신속하게 교체할 수 있다는 점 또한 Rescale 플랫폼에서 제공하는 장점 중 하나이다.
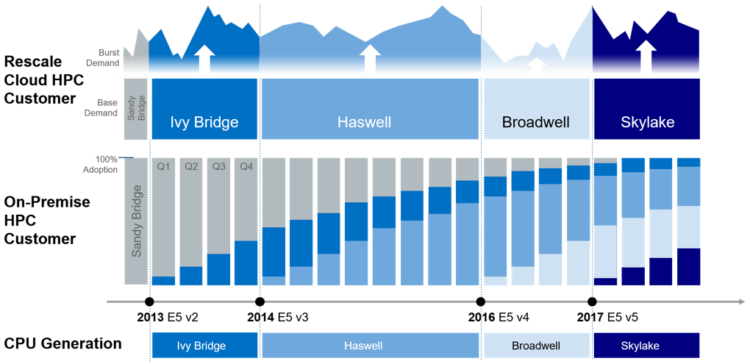
▲Rescale ScaleX 플랫폼을 활용하여 구형 아키텍쳐를 최신 아키텍쳐로 신속하게 전환
클라우드 업체는 2~3년 주기로 발표되는 최신 아키텍쳐의 클러스터를 지속적으로 도입하며, 클라우드 업체에 신규 클러스터가 도입되면 한 달 이내로 ScaleX 플랫폼에 통합되어 추가적인 계약 변경없이 최신 아키텍쳐를 사용할 수 있다. 이는 국내의 많은 기업들이 전산 장비 교체 주기를 5년으로 책정하거나 부분 전환 방식으로 교체하는 상황을 고려할 때 별도의 HPC 구성을 위한 복잡한 과정을 거치치 않고 신속하게 최신 아키텍쳐로 전환함으로써 보다 빠르게 시뮬레이션 업무를 수행할 수 있음을 의미한다.
Workflow 개선을 위한API 활용
앞서 Rescale 플랫폼 소개에서 워크로드에 적합한 코어 타입을 선정함으로써 시뮬레이션 속도를 향상시킬 수 있는 사례에 대하여 소개하였으며, 이어서 Rescale 플랫폼에서 제공하는 API를 활용하여 Workflow 개선을 통한 시뮬레이션 가속화 사례에 대하여 소개하고자 한다.
사용자의 요청에 따라 계산 노드를 생성하는 HPC 클라우드의 특성상 시뮬레이션 Workflow가 여러 단계로 나누어지거나Workflow 단계별 특성에 따라 멀티 코어의 활용이 제한되는 등 복잡해지는 경우 사용자 또한 시뮬레이션 수행에 필요한 작업에 소요되는 시간이 증가하게 되며 생산성 또한 저하되게 된다. 이를 보완하고자 사용자가 직접 웹 서버에 접속하여 파일을 업로드 및 다운로드하거나 작업의 생성 및 관리 등 Rescale 플랫폼에서 제공하는 기능들을 API로 구현해 놓았으며, 사용자는 이를 활용하여 여러 단계로 구성된 Workflow를 단순화하거나 보다 간편하게 비용 효율적인 시뮬레이션 Workflow를 구성할 수 있다.
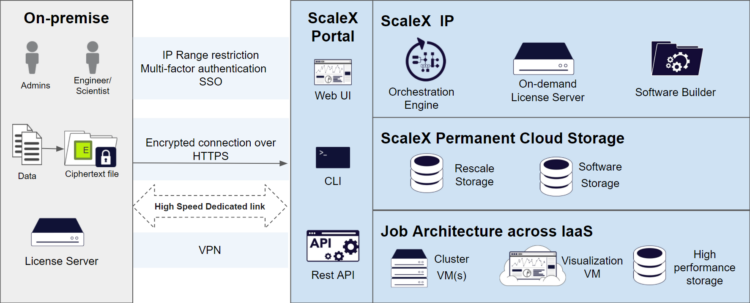
▲Rescale 표준 아키텍쳐
본격적으로 API 활용 사례를 소개하기에 앞서 사용자가 Rescale 플랫폼을 활용하는 방식은 총 3가지로 가장 일반적인 경우는 웹페이지에서 직접 interactive하게 작업을 하거나, CLI 및 API를 활용하여 시뮬레이션과 관련된 모든 작업을 스크립트를 활용하여 자동화할 수 있다. CLI의 경우 API와 활용 목적은 동일하나 API의 기능을 간소화하여 응용프로그램 형태로 제공하는 방식으로 간단한 명령어를 사용하여 복잡한 Workflow를 구성하는데 한계가 있다. 마지막으로API의 경우 Python 혹은 curl을 활용할 수 있으나 데이터 전처리, 시뮬레이션 결과의 후처리 편의성 등을 고려하여Python 스크립트로 작성하는 경우가 많다.
활용 사례로 소개할 내용은 API를 활용하여 ANSYS HFSS 시뮬레이션의 Workflow의 일부 단계를 통합하여 비용 효율적인 방식으로 재구성한 사례이며 테스트 모델 및 1차 성능 비교 결과는 아래와 같다.
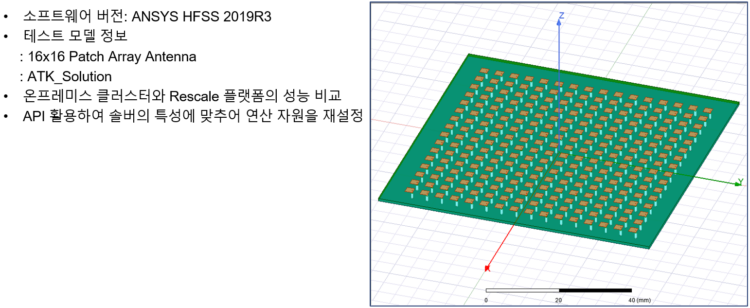
▲ANSYS HFSS 2-Step 시뮬레이션 모델
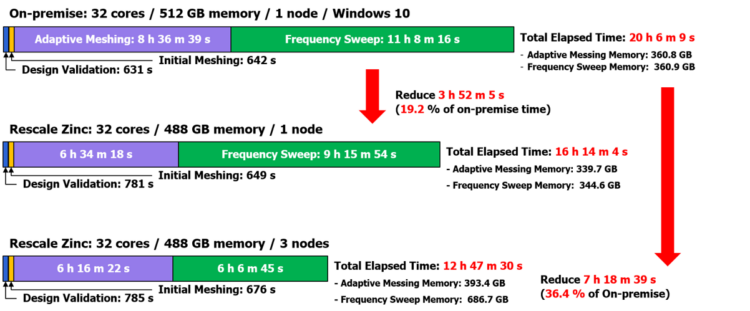
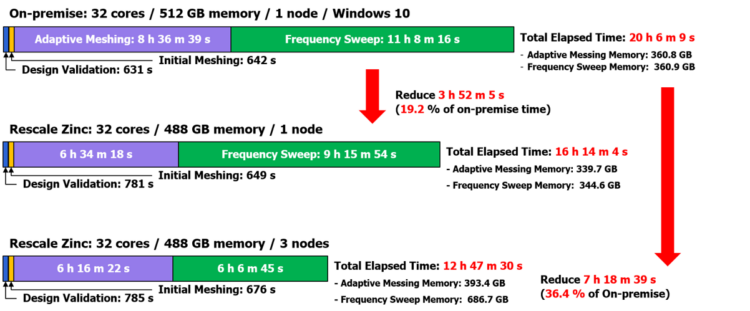
▲ANSYS HFSS on-prem vs Rescale 성능 비교 결과
테스트 모델을 활용하여 동일한 코어 수로 구성된 단일 노드간 비교 결과 on-premise(고객사 로컬) 대비 시뮬레이션 시간을 약 19% 단축하였으며, 3개의 노드를 사용 시 다중 노드를 활용하여 계산하는 Frequency Sweep 단계를 기존 9시간에서 6시간으로 단축하여 on-premise 대비 약 36% 단축하였다.
다만 HFSS 시뮬레이션 Workflow의 경우 각 단계별로 다음과 같은 특성이 있으며, 작업 생성 시 지정하는 코어 수가 연산 비용과 직결되는 부분임을 고려할 때 Workflow별로 전산 자원의 재구성이 필요하였다.
위와 같은 특성상 다중 노드를 생성하며 전체 시뮬레이션을 진행할 경우 성능 향상 대비 비용이 크게 소모된다는 점을 고려하여 Initial Meshing 및 Adaptive Meshing은 단일 노드, Frequency Sweep은 다중 노드를 사용하는 2-Step으로 구성한 후 API를 활용하여 작업 생성 및 이전 단계의 결과 파일 가져오기 등 필요한 작업들을 자동화함으로써 사용자 편의성과 비용 효율성을 동시에 향상시켰다.
▲ANSYS HFSS 2-Step 시뮬레이션
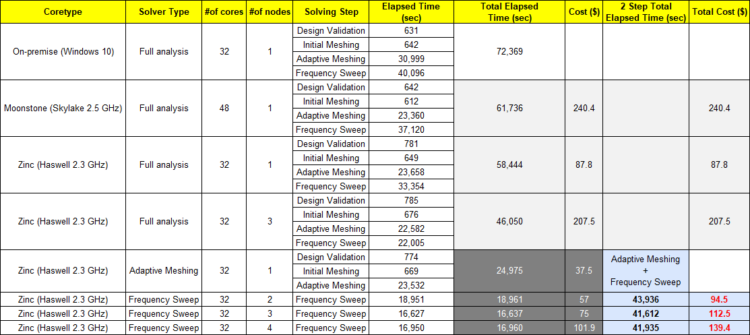
▲ANSYS HFSS 2-Step 시뮬레이션 소요 비용 비교
위 표의 Total Cost와 같이 2-Step 시뮬레이션으로 Workflow를 구성 시 3개의 노드로 Full analysis하는 경우 대비 시뮬레이션 시간은 1시간 14분 단축, 시뮬레이션 비용은 84% 절감할 수 있었으며, 수치상으로 나타나는 효과 외에도 사용자가 직접 플랫폼에 파일을 업로드하고 새로운 작업을 생성하는 등 필요한 과정에 소요되는 시간 또한 절감함으로써 전반적으로 시뮬레이션 업무를 가속화할 수 있었다.
Rescale의 ScaleX 플랫폼에 대한 소개와 Workflow 개선 사례 등 클라우드 HPC 플랫폼을 활용한 시뮬레이션 가속화 방안에 대하여 간략하게 공유하였다. 시뮬레이션이 제품 개발 사이클에서 차지하는 비중이 점차 증가하고 있으며, 다중 물리계 시뮬레이션이나 Machine learning 및 Deep learning과의 접목 등 최신 기술을 현업에 적용하기 위해서는 연산 자원의 뒷받침이 필수적이지만, 글로벌 경쟁 심화와 고정 비용의 절감을 동시에 달성해야 하는 기업들의 입장에서 대규모 HPC 시스템의 도입 또한 현실적으로 쉽지 않으므로 연산 자원이 필요한 기간에만 즉각적으로 사용할 수 있는 클라우드 HPC 플랫폼이 대안 중 하나가 될 수 있을 것으로 판단된다.
필자: 김정훈, Rescale Korea의 Solutions Architect로 주로 자동차 산업군 고객들의 HPC cloud 활용을 위한 기술지원을 담당하고 있다. 이메일: junghoon@rescale.com