이 글은 John Snow Labs의 선임 클라우드 솔루션 아키텍트 인 Moritz Steller와 공동으로 작성한 게시물입니다. 새로운 NLP 솔루션에 대해 알아보기 위해 7 월 15 일에 진행되는 가상 워크숍 인 Extract Real-World Data with NLP를 놓치지 마세요.
2015 년 HIMSS는 미국의 의료 산업이 12 억 개의 임상 문서를 생성 했다고 추정했습니다 . 이것은 엄청난 양의 비정형 텍스트 데이터입니다. 그 이후로 의료의 디지털화는 매년 생성되는 임상 텍스트 데이터의 양만 증가 시켰습니다. 디지털 양식, 온라인 포털, pdf 보고서, 이메일, 문자 메시지 및 챗봇은 모두 최신 의료 커뮤니케이션을위한 백본을 제공합니다. 이러한 채널에서 생성되는 텍스트의 양은 측정하기에는 너무 방대하고 사람이 소비하기에는 너무 포괄적입니다. 그리고 이러한 데이터 세트는 구조화되지 않았기 때문에 쉽게 분석 할 수 없으며 종종 사일로 상태로 유지됩니다.
이는 모든 의료 기관에 위험을 초래합니다. 이러한 실험실 보고서, 공급자 메모 및 채팅 로그에 잠긴 것은 중요한 정보입니다. 환자의 전자 건강 기록 (EHR)과 결합 될 때 이러한 데이터 포인트는 환자의 건강에 대한보다 완전한보기를 제공합니다. 인구 수준에서 이러한 데이터 세트는 신약 발견, 치료 경로 및 실제 안전성 평가에 정보를 제공 할 수 있습니다.
좋은 소식이 있습니다. 컴퓨터가 문자, 음성 또는 이미지 텍스트를 이해할 수 있도록 하는 인공 지능의 한 분야 인 자연어 처리 (NLP)의 발전으로 텍스트에서 인사이트을 추출 할 수 있습니다. NLP 방법을 사용하면 구조화되지 않은 임상 텍스트를 추출, 코드화 및 다운 스트림 분석을 위해 구조화 된 형식으로 저장하고 기계 학습 (ML) 모델에 직접 공급할 수 있습니다. 이러한 기술은 연구 및 관리 분야에서 중요한 혁신을 주도하고 있습니다.
사용 사례 에서 미국에서 가장 큰 비영리 의료 보험 및 의료 서비스 제공 업체 중 하나 인 Kaiser Permanente는 NLP를 사용하여 수백만 개의 응급실 분류 기록을 처리하여 병원 침대, 간호사 및 임상의에 대한 수요를 예측하고 궁극적으로 환자 흐름을 개선했습니다. 또 다른 연구 에서는 NLP를 사용하여 HIV 양성 청소년을 위한 모바일 지원 그룹의 비표준 문자 메시지를 분석했습니다. 분석은 그룹과의 참여, 개선 된 약물 순응도 및 사회적지지 감 사이에 강한 상관 관계를 발견했습니다.
이 모든 놀라운 혁신으로 인해 더 많은 의료 기관이 임상 텍스트 데이터를 사용하지 않는 이유는 무엇입니까? 경험상 가장 큰 지불 자, 공급자 및 제약 회사와 협력하면서 다음과 같은 세 가지 주요 과제를 확인했습니다.
NLP 시스템은 일반적으로 의료용으로 설계되지 않았습니다. 임상 텍스트는 자체 언어 입니다. 다양한 소스 시스템 (예 : EHR, 임상 노트, PDF 보고서)으로 인해 데이터가 일치하지 않으며, 그 외에도 임상 전문 분야에 따라 언어가 크게 다릅니다. 전통적인 NLP 기술은 의료 텍스트의 고유 한 어휘, 문법 및 의도를 이해하도록 구축되지 않았습니다. 예를 들어 아래 텍스트 문자열에서 NLP 모델은 아지트로 마이신 이 약물이고, 500mg 이 복용량이며, SOB 가 환자 상태 폐렴 과 관련된 "숨가쁨"의 임상 약어 임을 이해해야합니다.. 환자가 숨이가 쁘지 않다는 것과 단지 처방 된 이후로 아직 약을 복용하지 않았 음을 추론하는 것도 중요합니다.

대부분의 NLP 도구는 의료 텍스트를 제대로 코딩 할 수 없습니다. Spark NLP for Healthcare는 도메인 별 언어를 이해하도록 설계된 알고리즘으로 제작되었습니다.
유연하지 않은 레거시 의료 데이터 아키텍처. 텍스트 데이터에는 수많은 정보가 포함되어 있지만 환자 건강에 대한 하나의 렌즈 만 제공합니다. 실제 가치는 텍스트 데이터를 다른 건강 데이터와 결합하여 환자에 대한 포괄적 인보기를 만드는 데 있습니다. 안타깝게도 데이터웨어 하우스에 구축 된 레거시 데이터 아키텍처는 스캔 된 보고서, 생의학 이미지, 게놈 시퀀스 및 의료 기기 스트림과 같은 구조화되지 않은 데이터에 대한 지원이 부족하여 환자 데이터를 조화시키는 것이 불가능합니다. 또한 이러한 아키텍처는 비용이 많이 들고 확장하기가 복잡합니다. 많은 양의 건강 데이터에 대한 간단한 임시 분석을 실행하는 데 몇 시간 또는 며칠이 걸릴 수 있습니다. 환자의 요구를 실시간으로 조정할 때 기다리는 시간이 너무 깁니다.
고급 분석 기능이 없습니다. 대부분의 의료 조직은 데이터웨어 하우스 및 BI 플랫폼에 분석을 구축했습니다. 이는 지난주에 사용 된 병상 수를 계산하는 것과 같은 설명 분석에 적합하지만 향후 병상 사용을 예측하는 AI / ML 기능이 부족합니다. AI에 투자 한 조직은 일반적으로 이러한 시스템을 사일로 화 된 볼트 온 솔루션으로 취급합니다. 이 접근 방식을 사용하려면 데이터를 여러 시스템에 복제해야하므로 일관되지 않은 분석이 발생하고 통찰력을 얻는 데 걸리는 시간이 느려집니다.
Databricks와 John Snow Labs (오픈 소스 Spark NLP 라이브러리, Spark NLP for Healthcare 및 Spark OCR 의 창시자)는 의료 및 생명 과학 조직이 대량의 텍스트 데이터를 다음으로 변환하는 데 초점을 맞춘 새로운 솔루션 제품군을 발표하게되어 기쁩니다. 참신한 환자 통찰력. 당사의 공동 솔루션은 모든 데이터, 분석 및 AI를위한 확장 가능한 플랫폼과 동급 최고의 의료 NLP 도구를 결합합니다.

Databricks Lakehouse Platform 및 John Snow Labs로 의료 NLP의 힘을 활용하십시오.
데이터웨어 하우스의 최고의 요소와 클라우드 데이터 레이크의 저비용, 유연성 및 규모를 결합한 최신 데이터 아키텍처 인 Databricks Lakehouse 플랫폼 이 기반 역할을합니다 . 이 단순화되고 확장 가능한 아키텍처를 통해 의료 시스템은 구조화, 반 구조화 및 비 구조화 등 모든 데이터를 전통적인 분석 및 데이터 과학을위한 단일 고성능 플랫폼으로 통합 할 수 있습니다.
Databricks Lakehouse 플랫폼의 핵심에는 Apache SparkTM 및 데이터 레이크에 성능, 안정성 및 거버넌스를 제공하는 오픈 소스 스토리지 계층 인 Delta Lake가 있습니다. 의료 기관은 원시 공급자 메모 및 PDF 실험실 보고서를 포함한 모든 데이터를 Delta Lake의 청동 수집 레이어에 저장할 수 있습니다. 이것은 데이터 변환을 적용하기 전에 진실의 근원을 보존합니다. 반대로 기존 데이터웨어 하우스에서는 데이터를로드하기 전에 변환이 발생합니다. 즉, 구조화되지 않은 텍스트에서 추출 된 모든 구조화 된 변수가 기본 텍스트와 연결이 끊어집니다.
이러한 기반을 바탕으로 의료 및 생명 과학 산업에서 가장 널리 사용되는 NLP 라이브러리 인 John Snow Labs의 의료용 Spark NLP가 있습니다. 이 소프트웨어는 최첨단 정확도로 임상 및 생물 의학 텍스트 데이터를 원활하게 추출, 분류 및 구조화합니다. 이는 200 개 이상의 사전 학습되고 정기적으로 업데이트되는 모델과 함께 최신 의료 관련 딥 러닝 및 전이 학습 기술의 프로덕션 등급, 확장 가능 및 학습 가능한 구현을 사용하여 수행 됩니다.
John Snow Labs의 소프트웨어 라이브러리의 주목할만한 기능은 다음과 같습니다.
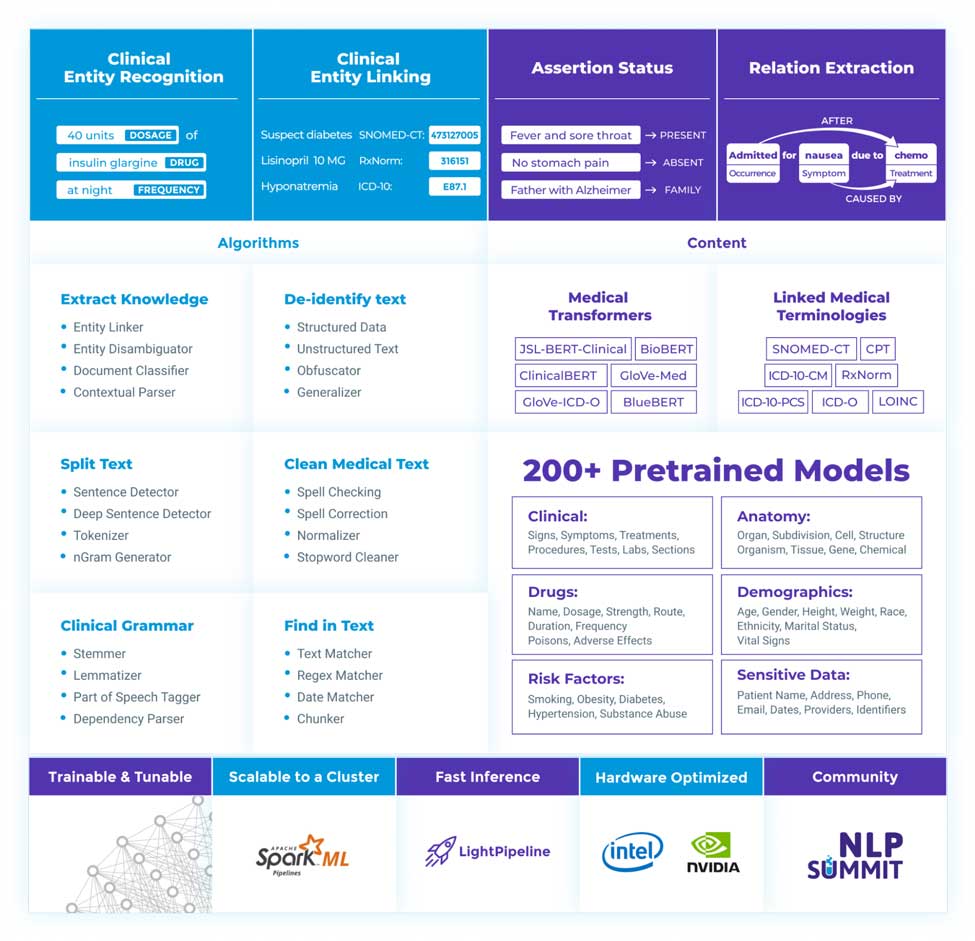
John Snow Labs의 Spark NLP for Healthcare 라이브러리는 업계에서 자연어 처리를위한 가장 강력한 기능 및 모델 집합 중 하나를 제공합니다.
당사의 공동 솔루션은 의료용 Spark NLP의 힘을 Databricks의 협업 분석 및 AI 기능과 결합합니다. 정보학 팀은 원시 데이터를 Databricks로 직접 수집하고, 의료용 Spark NLP를 사용하여 대규모 데이터를 처리하고, 다운 스트림 SQL 분석 및 ML에 모두 하나의 플랫폼에서 사용할 수 있도록 할 수 있습니다. 훈련 및 추론 프로세스는 모두 Databricks 내에서 직접 실행됩니다. 이는 속도와 규모의 이점 외에도 중요한 의료 데이터를 처리 할 때 중요한 개인 정보 보호 및 규정 준수 요구 사항 인 제 3 자에게 데이터가 전송되지 않음을 의미합니다. 무엇보다도 Databricks는 Apache SparkTM를 기반으로 구축되어 Spark NLP for Healthcare와 같은 Spark 애플리케이션을 실행하기에 가장 좋은 곳입니다.

Databricks 및 John Snow Labs를 사용하여 임상 텍스트를 포함한 모든 데이터를 처리, 분석 및 모델링하기위한 종단 간 워크 플로